

Examples
- Web Browser/Web Server
- Java Application: JDBC to Postgresql Server


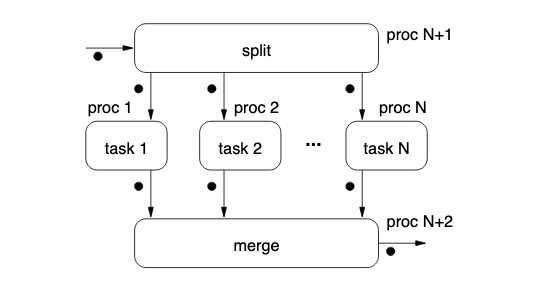
Example: Word Frequency
- Split file into chunks
- Give each worker a chunk
- Each worker computes frequency of words in chunk
- Sends cumulative work to single system for aggregation
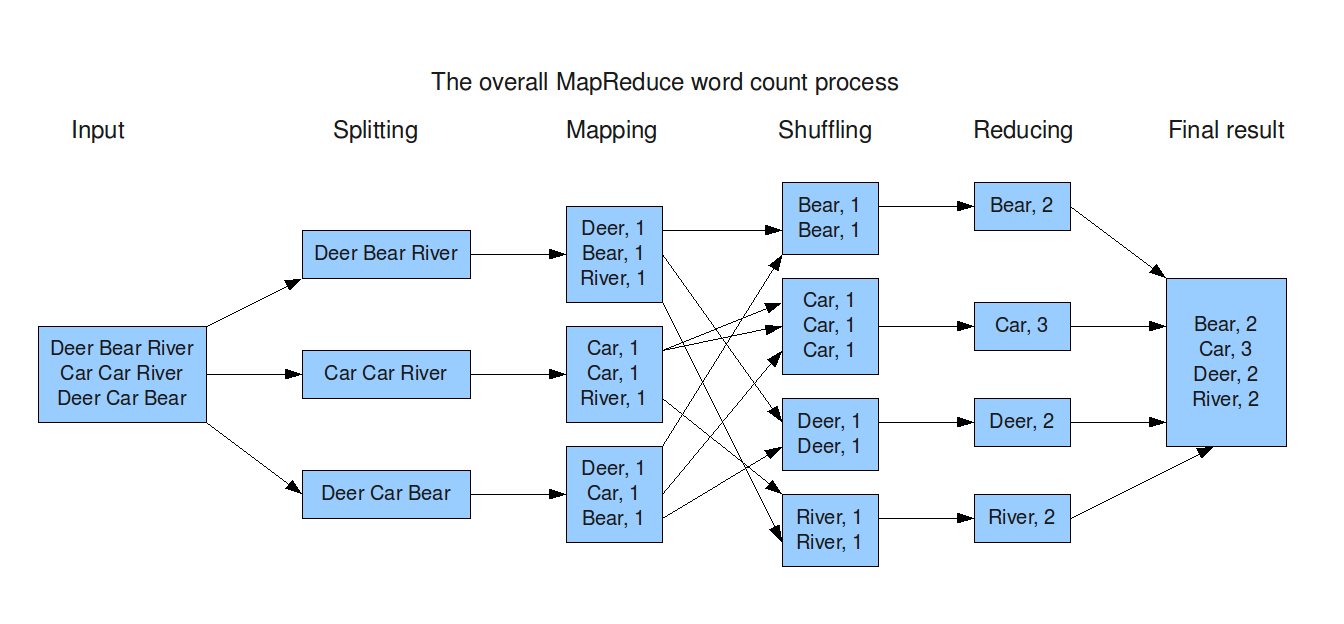
Example: Word Frequency
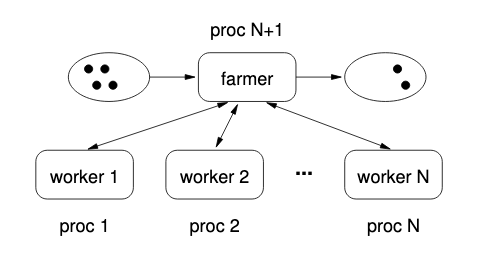
Example: Crack Hash
- Farmer: splits MD5 preimages into ranges, repeatedly gives work to workers when they ask. Get results from each worker as they complete and aggregate.
- Worker: If not busy, ask farmer for work, complete it, and give results back to farmer.

Example: Parallel Merge Sort

Example: SQL Server Mirroring


Example: Nginx Loadbalancer

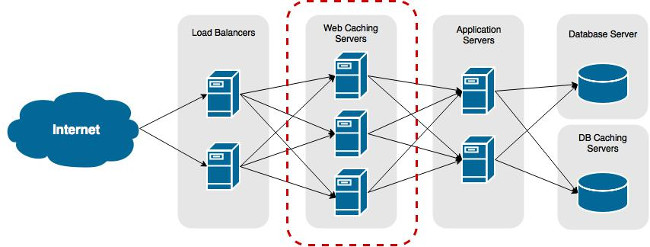
Example: Squid Proxy